1988年诺贝尔生理学和医学奖获得者Sir James Black 有一句名言: ‘The most fruitful basis of the discovery of a new drug is to start with an old drug’。发现一个老药的新靶点或作用机制,对于药理学家而言,就像生物学家发现一个基因或蛋白的新功能一样重要。

Posted by Luyao Ma on February 18, 2024
Posted in news
1988年诺贝尔生理学和医学奖获得者Sir James Black 有一句名言: ‘The most fruitful basis of the discovery of a new drug is to start with an old drug’。发现一个老药的新靶点或作用机制,对于药理学家而言,就像生物学家发现一个基因或蛋白的新功能一样重要。
Posted by Luyao Ma on January 26, 2024
Posted in news

英文原题:Structure-based Identification of Organoruthenium Compounds as Nanomolar Antagonists of Cannabinoid Receptors
Posted by Luyao Ma on January 22, 2024
Posted in news

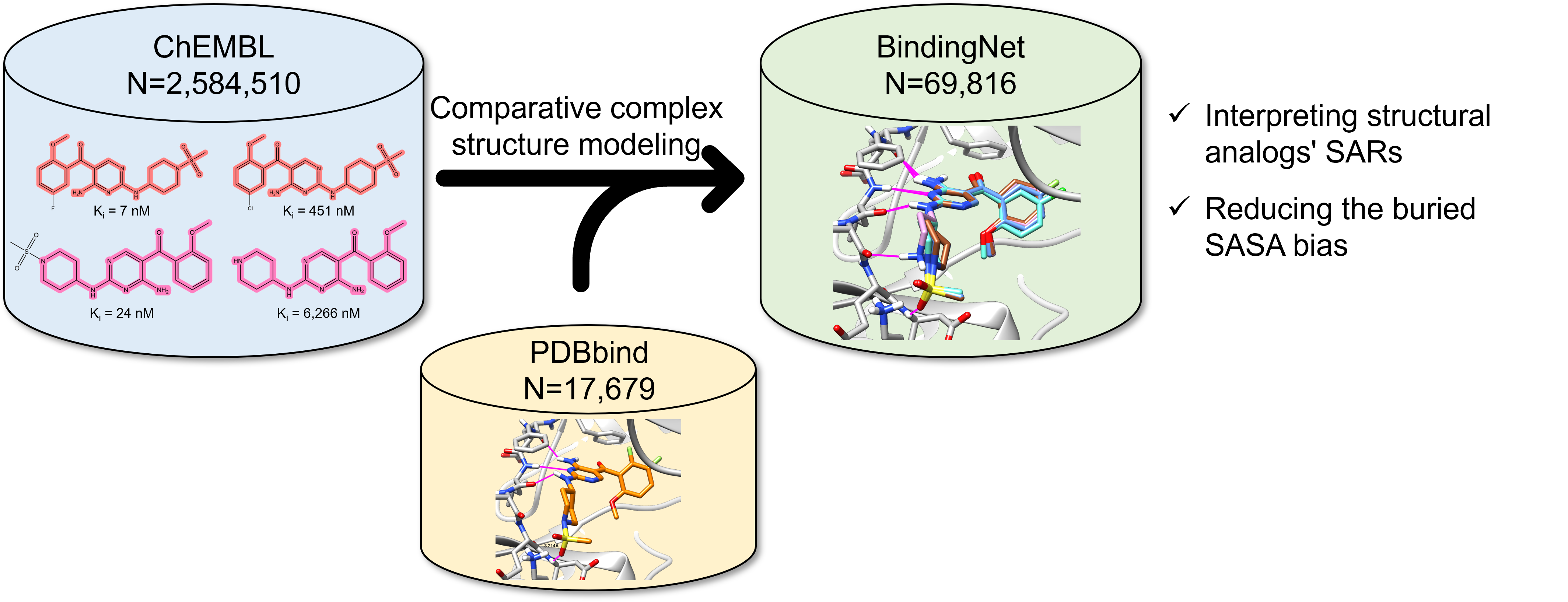
From Big Data to Good Data: 利用模板匹配方法构建高质量的蛋白-配体复合物结构模型数据集BindingNet
Posted by Luyao Ma on February 9, 2023
Posted in news

ACS Central Science | 以不变应万变:黄牛实验室利用虚拟筛选方法发现可调控新冠病毒刺突蛋白构象转变的小分子调节剂
Posted by Luyao Ma on February 9, 2023
Posted in news
【VIP来稿】北生所黄牛课题组Int J Mol Sci论文:雪中送炭还是锦上添花——基于靶标结构的虚筛为新药研发贡献了什么?